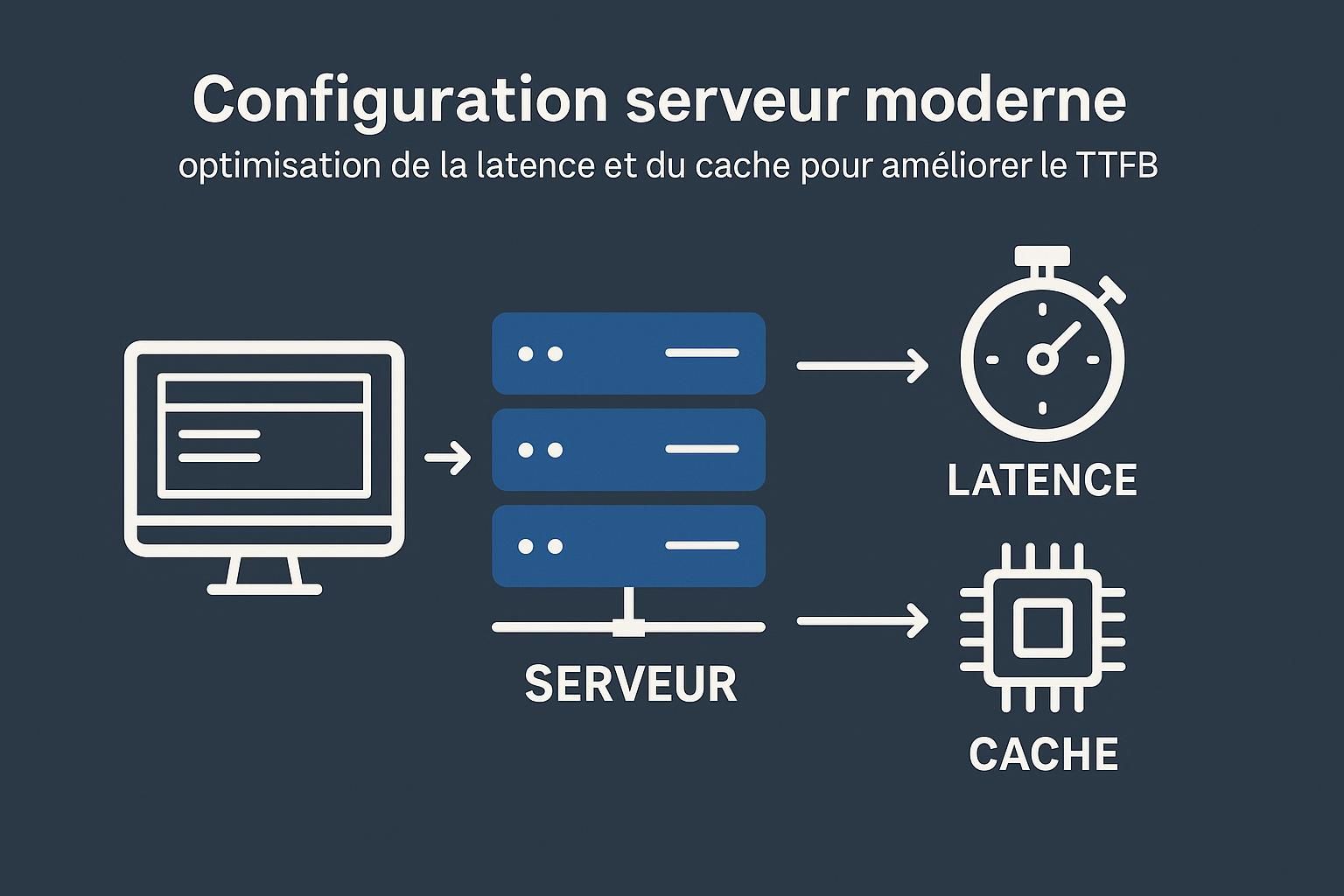
Le Time to First Byte (TTFB) dévoile l’essence même de la rapidité serveur, véritable colonne vertébrale pour tout site performant en 2026. Ce délai, mesurant le laps entre la requête initiale d’un navigateur et la réception du premier octet par ce dernier, ne se limite pas à un indicateur technique : il conditionne l’expérience utilisateur, influe sur le positionnement SEO et, in fine, impacte directement les revenus. Avec la montée en puissance du mobile et l’exigence croissante des internautes, un TTFB maîtrisé est devenu un standard incontournable. Pourtant, nombreux sont les sites freinés par des configurations inadaptées ou des couches back-end mal optimisées. Ce guide décortique la mécanique du TTFB, ses phases fondamentales – résolution DNS, connexion TCP/TLS, et traitement serveur – tout en proposant une série de solutions tangibles pour réduire efficacement ce temps.
Les enjeux dépassent la simple métrique : un TTFB trop élevé agit comme un goulot d’étranglement sur le chargement complet du site, multipliant les abandons précoces et dégradant inévitablement le référencement naturel, notamment la métrique clé Largest Contentful Paint (LCP). Analyser, mesurer avec rigueur grâce à des outils précis, puis ajuster l’hébergement, activer un cache serveur efficace, supprimer les requêtes SQL gourmandes et adopter une infrastructure moderne sont des étapes essentielles pour accélérer la performance serveur. En suivant ces pistes, les entreprises ne se contentent pas d’améliorer leur temps de chargement mais créent une dynamique vertueuse, à la fois technique et commerciale.
- Mesurer précisément le TTFB pour identifier les freins invisibles.
- Comprendre l’impact SEO et utilisateur d’un TTFB optimisé.
- Agir sur les ressources serveur : cache, PHP moderne, base de données.
- Choisir une infrastructure adaptée : VPS, cloud, CDN.
- Assurer un monitoring continu pour maintenir la performance dans le temps.
Pourquoi le TTFB est un indicateur stratégique pour la performance serveur en 2026
Le TTFB est le premier signal de réaction de votre serveur web face à une requête. Plus ce délai est faible, plus la chaîne technique – depuis la résolution du nom de domaine à la livraison du premier octet – est fluide. À l’inverse, un TTFB élevé bloque tout, quel que soit le degré d’optimisation site web effectué au niveau front-end. Cela signifie que même un site avec un cache navigateur parfaitement configuré ou un CSS minimisé butera sur un temps d’attente initial trop long. Cette friction engendre un effet domino : le temps de chargement global s’allonge, la frustration des utilisateurs augmente, et le référencement naturel en pâtit sérieusement.
Le rôle de Google dans cette dynamique ne fait que renforcer l’importance du TTFB. Depuis l’intégration des Core Web Vitals, ce délai est un critère essentiel au classement. Les chiffres sont implacables : un retard de 100 millisecondes peut se traduire par une chute tangible du trafic, et même un leader mondial du commerce électronique a évalué ses pertes à 1 % de chiffre d’affaires par centaine de millisecondes de latence. Ainsi, maîtriser le TTFB dépasse le simple cadre technique : c’est une condition sine qua non pour offrir une expérience utilisateur fluide et performante.

Les trois phases clés qui composent le TTFB
Pour agir efficacement, il faut d’abord comprendre le déroulement du TTFB en plusieurs étapes :
- Résolution DNS : Traduction du nom de domaine du site en adresse IP, un point critique où une mauvaise configuration peut ajouter jusqu’à 150 ms inutilement.
- Connexion TCP/TLS : Établissement d’une liaison sécurisée indispensable à la confidentialité des échanges. L’optimisation SSL ou TLS joue un rôle majeur dans la réduction de ce segment.
- Traitement serveur : Phase la plus consommatrice, elle englobe l’exécution du code backend, l’interrogation des bases de données, et la génération du contenu HTML. C’est le cœur de la performance serveur.
Chacune de ces phases offre des leviers d’amélioration précis, qu’il s’agisse de simplifier les requêtes internes, d’optimiser la couche PHP, ou d’adopter des serveurs plus puissants et mieux configurés. C’est en lisant précisément chaque segment de ce temps que l’optimisation prend tout son sens.
Comment diagnostiquer efficacement un TTFB trop élevé et identifier les goulots d’étranglement
Avant toute optimisation, un diagnostic rigoureux est indispensable. Passer à côté des causes précises d’un TTFB trop important risque de diluer les efforts et d’engendrer des interventions coûteuses sans résultats tangibles.
Parmi les outils incontournables, Google PageSpeed Insights se distingue par sa combinaison de données terrain réelles et de mesures en laboratoire, tandis que WebPageTest.org complète ce diagnostic en offrant une vision multi-localisation et un détail des interactions réseau. Pour une vue locale instantanée, Chrome DevTools en onglet Network permet d’analyser requête par requête et déceler les latences spécifiques. Enfin, curl en ligne de commande reste l’arme ultime pour isoler le temps serveur purement technique sans overhead navigateur.
Voici un exemple de mesure avec curl :
curl -o /dev/null -s -w « DNS: %{time_namelookup}snConnect: %{time_connect}snTLS: %{time_appconnect}snTTFB: %{time_starttransfer}snTotal: %{time_total}sn » https://www.votre-site.com
Comparer les résultats donne souvent un aperçu immédiat de l’état d’optimisation du serveur. Un site bien configuré tourne autour de 200 ms de TTFB, tandis qu’un serveur mal dimensionné peut dépasser la seconde et plomber l’ensemble de la chaîne de chargement.
Les sources les plus fréquentes d’un TTFB élevé et leurs symptômes caractéristiques
Plusieurs causes, souvent conjuguées, expliquent un TTFB au-delà des seuils recommandés :
- Hébergement sous-dimensionné : une machine partagée ou aux ressources limitées provoque des pics de latence, notamment aux heures de pointe.
- Absence de cache serveur : sans mise en cache, chaque requête active une charge complète de calcul, aggravant les délais.
- Requêtes SQL inefficaces : des bases de données mal indexées ou des requêtes lourdes ralentissent sensiblement la génération du contenu.
- Versions PHP vieillissantes : exploiter les dernières versions, notamment PHP 8.2 ou 8.3, permet des gains notables de vitesse via le compilateur JIT.
- Plugins ou modules mal optimisés : effet boule de neige provoqué par des extensions qui surchargent le backend.
- Absence de CDN : la localisation géographique du visiteur par rapport au serveur influence directement le TTFB, un CDN réduit drastiquement cette latence.
- Mauvaise configuration DNS : un DNS lent ou mal paramétré ajoute un temps mort non nécessaire.
Les caractéristiques observées permettent d’orienter rapidement le diagnostic : fluctuations TTFB selon l’heure, lenteurs uniquement sur certaines pages, ou impact des modules activés. Reconnaître ces signes évite les interventions générales inefficaces et cible les axes prioritaires.
Les bonnes pratiques et solutions pour réduire efficacement votre TTFB et accélérer site
Les leviers d’action disponibles s’ordonnent selon leur impact et leur facilité d’implémentation. Commençons par le plus puissant :
- Installer un cache serveur robuste : système clé dans la chaîne, il permet de délivrer instantanément les pages pré-générées à la place des requêtes dynamiques. Redis, Memcached, OPcache et plugins spécialisés (WP Rocket, W3 Total Cache) optimisent ce processus.
- Optimiser la base de données : activer les logs de requêtes lentes, analyser avec EXPLAIN pour ajouter les indexes nécessaires, et éviter les requêtes globales non ciblées.
- Adopter un hébergement adapté : privilégier VPS, serveurs dédiés ou cloud (Amazon EC2 associé à ElastiCache) plutôt que du mutualisé à bas coût.
- Déployer un CDN : distribuer les contenus statiques et dynamiques via Cloudflare, AWS CloudFront ou Fastly réduit significativement la latence réseau.
- Mettre à jour PHP et configurer le serveur web : basculer vers Nginx avec PHP-FPM, activer OPcache avec buffer mémoire généreux et JIT.
- Réduire les appels externes sur le serveur : stocker les réponses API en cache, différer les appels non critiques côté client.
L’efficacité cumulée de ces actions peut faire chuter un TTFB de plus d’une seconde à quelques centaines de millisecondes, impactant directement la vitesse de chargement et la perception utilisateur.
Étude de cas : Quand un site PrestaShop réduit son TTFB de 1,8 seconde à 180 millisecondes
Prenons l’exemple d’une boutique e-commerce avec 15 000 produits sous PrestaShop confrontée à un TTFB élevé, débutant par une infrastructure mutualisée peu adaptée et une version PHP datée. Après avoir migré vers AWS EC2, activé ElastiCache Redis, et modernisé PHP vers la version 8.2 avec OPcache JIT, l’équipe technique a désactivé 19 modules superflus et ajouté des indexes cruciaux sur la base de données. L’introduction de Nginx avec cache FastCGI et la mise en place de CloudFront en CDN ont complété la transformation.
Les résultats sont impressionnants :
- TTFB moyen réduit de 1 847 ms à 182 ms
- LCP divisé par 3, passant à 1,4 seconde
- Diminution du taux de rebond de 23 %
- Augmentation du taux de conversion de 18 % en trois mois
Cette démonstration illustre la maîtrise complète des leviers du temps de chargement pour façonner une expérience utilisateur optimale synonyme de gains commerciaux concrets.